객체지향 쿼리 언어 - JPQL
10. 객체지향 쿼리 언어
10.1 객제치향 쿼리 소개 - JPQL
- EntityManager.find() 메소드는 식별자로 엔티티 하나를 조회한다.
- 특정 조건을 만족하는 여러 엔티티를 조회할 때 EntityManager.find() 메소드를 이용하면 모든 엔티티를 메모리에 올려두고 애플리케이션에서 검색해야한다. 비효율적인 방법이다.
- 따라서 데이터베이스에서 SQL로 필요한 내용을 최대한 걸러서 조회해야 한다. SQL은 데이터베이 테이블을 대상으로 조회하기 때문에 엔티티 객체를 대상으로 조회하기 위해 JPQL을 사용한다.
- JPA는 JPQL을 분석하여 적절한 SQL을 만들어 데이터베이스를 조회한다.
- JPQL은 SQL을 추상화해서 특정 데이터베이스에 의존하지 않는다. 방언을 이용하여 JPQL을 수정하지 않아도 데이터베이스를 변경할 수 있다.
10.2 JPQL
10.2.1 기본 문법과 쿼리 API
- JPQL은 SELECT, UPDATE, DELETE 문을 사용할 수 있다.
- INSERT 문은 없다. EntityManager.persist() 메소드를 사용하여 데이터를 추가한다.
1. SELECT 문
select m from Member as m where m.username='Hello'
- 대소문자 구분: 엔티티와 속성은 대소문자를 구분한다. JPQL 키워드는 대소문자를 구분하지 않는다.
- Member는 클래스이름이 아니라 엔티티 이름이다.
- JPQL은 별칭을 필수로 사용해야 한다. as는 생략 가능하다.
2. TypeQuery vs Query
TypedQuery<Member> query = em.createQuery("select m from Member m", Member.class);
List<Member> result = query.getResultList();
for (Member member : result) {
System.out.println("member = " + member);
}
// SELECT 절의 조회 대상이 둘 이상이면 Object[]을 반환, 하나면 Object 반환
Query query = em.createQuery("select m.username, m.age from Member m");
List<Object[]> result = query.getResultList();
for (Object[] o : result) {
System.out.println(o[0]);
System.out.println(o[1]);
}
- 반환 타입이 명확하면 TypedQuery 객체 사용
- 반환 타입이 명확하지 않으면 Query 객체 사용
3. 결과 조회
- query.getResultList(): 결과가 없으면 빈 컬렉션 반환
- query.getSingleResult(): 결과가 정확히 하나일 때 사용, 결과가 없거나 1개 보다 많으면 예외 발생
10.2.2 파라미터 바인딩
- 이름 기준 파라미터 바인딩 방식을 사용하는 것이 명확하다.
// 이름 기준 파라미터
List<Member> result = em.createQuery("select m from Member m where m.username = :username", Member.class)
.setParameter("username", "User1")
.getResultList();
// 위치 기준 파라미터, 위치 값은 1부터 시작
List<Member> result = em.createQuery("select m from Member m where m.username = ?1", Member.class)
.setParameter(1, "User1")
.getResultList();
10.2.3 프로젝션
- SELECT 절에 조회할 대상을 지정하는 것을 말한다.
- “SELECT [프로젝션 대상] FROM”
- 프로젝션 대상은 엔티티, 임베디드 타입, 스칼라 타입(문자, 숫자 등 기본 데이터 타입)
1. 엔티티 프로젝션
- 영속성 컨텍스트에서 관리된다.
select m from Member m
select m.team from Member m
2. 임베디드 타입 프로젝션
- 조회의 시작점이 될 수 없다.
- 엔티티를 통해서 조회해야 한다.
- 값 타입이므로 영속성 컨텍스트에서 관리되지 않는다.
List<Address> addresses1 = em.createQuery("select a from Address a", Address.class).getResultList(); // 잘못된 쿼리
List<Address> addresses2 = em.createQuery("select o.address from Order o", Address.class).getResultList(); // 정상 쿼리
3. 스칼라 타입 프로젝션
- 문자, 숫자, 날짜와 같은 기본 데이터 타입
List<String> result = em.createQuery("select m.username from Member m", String.class).getResultList();
4. 여러 값 조회
- 여러 값 조회시 TypeQuery 사용불가, Query를 사용해야 한다. TypeQuery vs Query 참고
List<Object[]> resultList = em.createQuery("select m.username, m.age from Member m").getResultList();
5. NEW 명령어
- 여러 값 조회시 Object[]보다 DTO객체를 이용한다.
- SELECT 다음 NEW 명령어를 사용하여 DTO 객체를 바로 만들 수 있다.
- 패키지 명을 포함한 전체 클래스 명을 입력해야 한다.
- 순서와 타입이 일치하는 생성자가 필요하다.
public class UserDto {
private String username;
private int age;
public UserDto(String username, int age) {
this.username = username;
this.age = age;
}
}
List<UserDto> users = em.createQuery("select new jpabook.example.UserDto(m.username, m.age) from Member m", UserDto.class).getResultList();
10.2.4 페이징 API
- 데이터베이스마다 페이징 처리 SQL 문법이 다르다. 방언을 이용하여 데이터베이스마다 다른 문법을 같은 API로 처리할 수 있다.
- JPA는 페이징을 다음 두 API로 추상화했다.
- setFirstResult(): 조회 시작위치, 0부터 시작한다.
- setMaxResults(): 조회할 데이터 수
List<Member> result = em.createQuery("select m from Member m order by m.age desc", Member.class)
.setFirstResult(1)
.setMaxResults(5)
.getResultList();
10.2.5 집합과 정렬
1. 집합 함수
Object result = em.createQuery("select count(m), sum(m.age), avg(m.age), max(m.age), min(m.age) from Member m").getSingleResult();
Object[] o = (Object[]) result;
System.out.println(o[0]); // COUNT
System.out.println(o[1]); // SUM
System.out.println(o[2]); // AVG
System.out.println(o[3]); // MAX
System.out.println(o[4]); // MIN
2. GROUB BY, HAVING
List<Object[]> result = em.createQuery("select t.name, count(m), sum(m.age), avg(m.age), max(m.age), min(m.age) " +
"from Member m left join m.team t " +
"where m.age > 8 " +
"group by t.name " +
"having avg(m.age) > 4 ")
.getResultList();
GROUP BY와 HAVING절까지 기술한 SELECT구문을 해석하면 아래와 같다.
- from절에 기술한 테이블에서
- where절에 기술한 조건에 해당하는 내용들만 정리하고
- 정리된 내용들을 가지고 group by절에 나열된 컬럼에 대해서 그룹을 만든다.
- 만들어진 그룹별로 having절에 기술된 그룹함수로 계산하여 having절 조건에 맞는 그룹만 추리고
- 추려진 그룹들을 order by절에 잇는 조건으로 정렬시킨다.
- 마지막으로 select절에 있는 그룹화된 컬럼 또는 그룹함수를 화면에 출력한다.
3. 정렬
- 아래 쿼리는 나이를 기준으로 내림차순, 나이가 같으면 이름을 기준으로 오름차순으로 정렬한다.
List<Member> result = em.createQuery("select m from Member m order by m.age DESC, m.username ASC", Member.class).getResultList();
10.2.6 JPQL 조인
1. 내부 조인
- JPQL 내부 조인 구문과 SQL 조인 구문은 약간 다르다. 연관 필드로 조인한다.
- select절에 있는 엔티티만 불러온다.
List<Member> result = em.createQuery("select m from Member m join m.team t where t.name = :teamName", Member.class)
.setParameter("teamName", "team1")
.getResultList();
select m.id, m.age, m.team_id, m.username
from Member m
inner join Team t on m.team_id=t.id
where t.name=?
- 조인한 두 개의 엔티티를 조회하려면 아래와 같이 사용한다. 또는 페치 조인을 사용한다.
List<Object[]> result = em.createQuery("select m, t from Member m join m.team t")
.getResultList();
for (Object[] o : result) {
Member member = (Member) o[0];
System.out.println(member.getUsername() + " " + member.getAge() + " " + member.getTeam().getName());
}
2. 외부 조인
List<Member> result = em.createQuery("select m from Member m left join m.team t", Member.class)
.getResultList();
select m.id, m.age, m.team_id, m.username
from Member m
left outer join Team t on m.team_id=t.id
3. 컬렉션 조인
- 일대다 관계나 다대다 관계에서는 컬렉션을 사용한다.
- 팀 엔티티의 회원 필드는 컬렉션 연관 필드를 사용한다.
List<Object[]> result = em.createQuery("select t, m from Team t left join t.result m")
.getResultList();
for (Object[] o : result) {
Team team = (Team) o[0];
Member member = (Member) o[1];
System.out.println(member.getUsername() + " " + member.getAge() + " " + member.getTeam().getName());
}
select t.id, m.id, t.name, m.age, m.team_id, m.username
from Team t
left outer join Member m on t.id=m.team_id
4. 세타 조인
- 관련없는 Member.username과 Team.name을 조인한다.
- 테이블1과 테이블2를 교차 조인하면 각 테이블의 행의 수를 곱한 것과 같은 개수의 결과 행이 생긴다.
List<Member> result = em.createQuery("select m from Member m, Team t where m.username=t.name", Member.class)
.getResultList();
select m.id, m.age, m.team_id, m.username
from Member m
cross join Team t where m.username=t.name
5. JOIN ON 절
- 내부 조인의 ON 절은 WHERE 절을 사용할 때와 결과가 같다.
- 보통 ON 절은 외부 조인에서 사용한다.
- 외부 조인 ON 절 vs 외부 조인 WHERE 절
- ON 절: 모든 회원을 조회하는데 팀 이름이 “team1” 인 경우에 조인한다. (left join 기준)
- WHERE 절: 조인 이후 필터링, 따라서 “team1” 인 모든 회원 조회, 내부 조인이랑 결과가 같다.
List<Object[]> result = em.createQuery("select m, t from Member m left join m.team t on t.name = :teamName")
.setParameter("teamName", "team1")
.getResultList();
select m.id, t.id, m.age, m.team_id, m.username, t.name
from Member m
left outer join Team t on m.team_id=t.id and (t.name=?)
10.2.7 페치 조인
- 연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능이다.
1. 엔티티 페치 조인
- 회원과 연관된 팀을 함께 조회
- 페치 조인은 별칭을 사용할 수 없다.(JPA 표준은 사용할 수 없고, 하이버네이트는 지원한다.)
List<Member> result = em.createQuery("select m from Member m join fetch m.team", Member.class)
.getResultList();
for (Member member: result) {
// 페치 조인으로 회원과 팀을 함께 조회해서 지연 로딩 발생안함
System.out.println(member.getUsername() + " " + member.getAge() + " " + member.getTeam().getName());
}
select m.id, t.id, m.age, m.team_id, m.username, t.name
from Member m
inner join Team t on m.team_id=t.id
2. 컬렉션 페치 조인
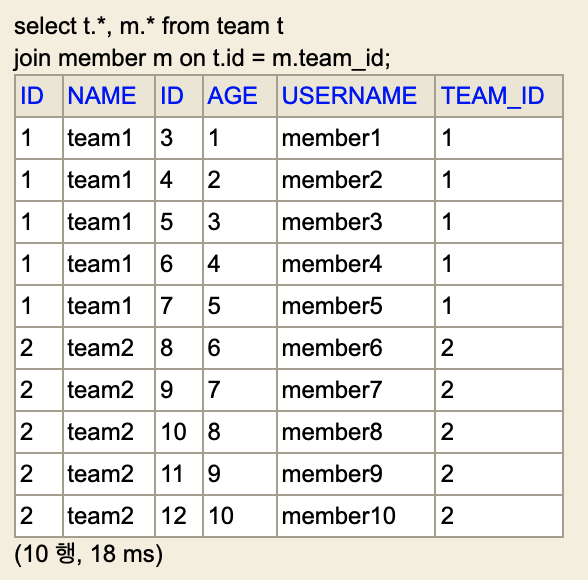
- 일대다 관계 컬렉션을 아래와 같이 페치조인하면, 데이터베이스에 팀은 2개지만 결과 리스트에는 10개가 조회된다.
- 테이블 조인시 회원의 수 만큼 팀의 결과가 증가하기 때문이다.
List<Team> result = em.createQuery("select t from Team t join fetch t.members", Team.class)
.getResultList();
System.out.println(result.size()); // 10이 출력됨
for (Team team: result) {
System.out.println("team.getName() = " + team.getName());
List<Member> members = team.getMembers();
for (Member member : members) {
System.out.println(member.getUsername() + " " + member.getAge() + " " + member.getTeam().getName());
}
}
select t.id, m.id, t.name, m.age, m.team_id, m.username, m.team_id, m.id
from Team t
inner join Member m on t.id=m.team_id
3. 페치 조인과 DISTINCT
- SQL의 DISTINCT는 중복된 결과를 제거하는 명령어이다.
- JPQL의 DISTINCT는 SQL에 DISTINCT를 추가하고, 애플리케이션에서 한 번 더 중복을 제거한다.
- 위의 조인 결과에서 SQL에 DISTINCT를 추가하여도 각 로우의 데이터가 다르므로 효과가 없지만, JPA가 애플리케이션에서 중복을 한 번 더 제거하기 때문에 중복이 제거된다.
List<Team> result = em.createQuery("select distinct t from Team t join fetch t.members", Team.class)
.getResultList();
4. 페치 조인과 일반 조인의 차이
- JPQL은 SELECT절에 지정한 엔티티만 조회한다.
- 따라서 아래 일반 조인은 SELECT절에 지정한 팀만 조회한다.
- 연관된 엔티티를 지연 로딩으로 설정하면 프록시나 컬랙션 래퍼를 반환하고, 즉시 로딩으로 설정하면 쿼리가 한 번 더 실행된다. 따라서 한번에 조회하려면 페치 조인을 사용해야 한다.
List<Team> result = em.createQuery("select t from Team t join t.members m", Team.class)
.getResultList();
-- 일반 조인
select t.id, t.name
from Team t
inner join Member m on t.id=m.team_id
List<Team> result = em.createQuery("select t from Team t join fetch t.members", Team.class)
.getResultList();
select t.id, m.id, t.name, m.age, m.team_id, m.username, m.team_id, m.id
from Team t
inner join Member m on t.id=m.team_id
5. 페치 조인의 특징과 한계
- 페치 조인을 사용하면 SQL 한 번으로 연관된 엔티티들을 함께 조회할 수 있어서 SQL 호출 횟수를 줄여 성능 최적화를 할 수 있다.
- 페치 조인은 글로벌 로딩 전략보다 우선한다. 지연 로딩으로 설정해도 페치 조인 사용시 즉시 로딩된다.
- 페치 조인 대상에는 별칭을 줄 수 없다. JPA 표준에서는 지원하지 않지만 하이버네이트에서 지원한다. 하지만 추천하지 않는다.
- 둘 이상의 컬렉션을 페치 조인 할 수 없다.
- 컬렉션을 페치 조인하면 페이징 API를 사용할 수 없다. 하이버네이트에서 컬렉션 페치 조인하고 페이징 API를 사용하면 메모리에서 페이징 처리를 하므로 데이터가 많으면 위험하다.
10.2.8 경로 표현식
- 경로 표현식이란 객체 그래프를 탐색하는 것을 말한다.
- 아래 코드에서 m.username, m.team, m.orders, t.name이 모두 경로 표현식이다.
List result = em.createQuery("select m.username from Member m join m.team t join m.orders o where t.name = 'team1'")
.getResultList();
1. 경로 표현식 용어 정리
- 상태 필드: 단순 값 저장 필드
- ex) m.username, m.age
- 연관 필드: 연관관계를 위한 필드, 임베디드 타입 포함
- 단일 값 연관 필드: @ManyToOne, @OneToOne
- ex) m.team
- 컬렉션 값 연관 필드: @OneToMany, @ManyToMany
- ex) m.orders
- 단일 값 연관 필드: @ManyToOne, @OneToOne
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
private String username;
private int age;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<>();
}
2. 경로 표현식과 특징
1) 상태 필드 경로
- 경로 탐색의 끝이다. 더이상 탐색이 불가하다.
ist<Object[]> result = em.createQuery("select m.username, m.age from Member m")
.getResultList();
select m.username, m.age
from Member m
2) 단일 값 연관 경로
- 묵시적으로 내부 조인이 일어난다. 계속 탐색할 수 있다.
- 단일 값 연관 필드로 경로 탐색을 하면 SQL 에서 내부 조인이 일어나는데 이것을 묵시적 조인이라 한다. 묵시적 조인은 모두 내부 조인이다.
List<Team> result = em.createQuery("select m.team from Member m", Team.class)
.getResultList();
select t.id, t.name
from Member m
inner join Team t on m.team_id=t.id
- 아래는 좀 더 복잡한 쿼리로 order.member.team, order.product 연관 관계로 인하여 3번의 조인이 발생한다.
- order.address는 값 타입으로 order 테이블에 이미 포함되어 있어 조인이 발생하지 않는다.
List<Team> result = em.createQuery("select o.member.team from Order o where o.product.name = 'productA' and o.address.city = 'JINJU'", Team.class)
.getResultList();
select t.id, t.name
from orders o
cross join Member m
inner join Team t on m.team_id=t.id
cross join Product p
where o.member_id=m.id and o.product_id=p.id and p.name='productA' and o.city='JINJU'
3) 컬렉션 값 연관 경로
- 묵시적으로 내부 조인이 일어난다. 더는 탐색할 수 없다.
- 단 FROM 절 에서 조인을 통해 별칭을 얻으면 별칭으로 탐색할 수 있다.
- 컬렉션 크기를 구할 수 있는 size 기능을 사용할 수 있다.
select t.members from Team t -- 성공
select t.members.username from Team t -- 실패
select m.username from Team t join t.members m -- 성공
select t.members.size form Team t -- 성공
3. 경로 탐색을 사용한 묵시적 조인시 주의사항
- 항상 내부 조인이다.
- 컬렉션은 경로 탐색의 끝이다. 컬렉션으로 경로 탐색을 하려면 명시적으로 조인해서 별칭을 얻어야 한다.
- 경로 탐색은 주로 SELECT, WHERE 절에서 사용하지만 묵시적 조인으로 인해 SQL의 FROM 절에 영향을 준다.
- 묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 힘들기 때문에 명시적 조인을 사용하는 것을 추천한다.
10.2.9 서브 쿼리
- JPQL의 서브쿼리는 WHERE, HAVING 절에서만 사용할 수 있다. SELECT, FROM 절에서는 사용할 수 없다.
- 하이버네이트의 HQL은 SELECT 절의 서브 쿼리도 허용한다.
-- 나이가 평균보다 많은 회원
select m from Member m where m.age > (select avg(m2.age) from Member m2)
-- 한 건이라도 주문한 고객
select m from Member m where (select count(o) from Order o where m = o.member) > 0
select m from Member m where m.orders.size > 0
서브 쿼리 함수
1) EXISTS
- 서브쿼리에 결과가 존재하면 참이다.
-- TeamA 소속인 회원
select m from Member m where exists (select t from m.team t where t.name = 'TeamA')
select m from Member m join m.team t where t.name = 'TeamA'
2) ALL, ANY, SOME
- 비교 연산자와 같이 사용한다. ex) =, >, >=, <, <= <>
- ALL: 조건을 모두 만족하면 참이다.
- ANY, SOME: 조건을 하나라도 만족하면 참이다.
-- 전체 상품 각각의 재고보다 주문량이 많은 주문들
select o from Order o where o.orderAmount > all (select p.stockAmount from Product p)
-- 어떤 팀이든 팀에 소속된 회원
select m from Member m where m.team = any (select t from Team t)
select m from Member m join m.team t
3) IN
- 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참이다. IN은 서브쿼리가 아닌 곳에서도 사용한다.
-- 20세 이상을 보유한 팀
select t from Team t where t in (select t2 from Team t2 join t2.members m2 where m2.age >= 20)
10.2.10 조건식
1. 타입 표현
- 문자: ‘Hello’, ‘She’’s’
- 숫자: 10L, 10D, 10F
- 날짜: {d’2012-03-24’}, {t’10-11-11}, {ts’2012-03-24 10-11-11.123’}
- Boolean: TRUE, FALSE
- Enum: jpabook.MemberType.Admin
- 엔티티 타입: TYPE(m) = Member
2. 연산자 우선 순위
- 경로 탐색 연산(.)
- 수학 연산: +, -(단항연산자), *, /. +, -
- 비교 연산: =, >, >=, <, <=, <>, BETWEEN, LIKE, IN, IS NULL, IS EMPTY, MEMBER OF, EXISTS
- 논리 연산, NOT, AND, OR
3. 논리 연산과 비교식
- 논리 연산: AND, OR, NOT
- 비교식: =, >, >=, <, <=, <>
4. Between, IN, Like, NULL 비교
1) Beetween 식
- X BETWEEN A AND B: X는 A~B 사이의 값이면 참(A, B 값 포함)
select m from Member m where m.age between 10 and 20
2) IN 식
- X IN (예제): X와 같은 값이 예제에 하나라도 있으면 참이다.
select m from Member m where m.username in ('회원1', '회원2')
3) Like 식
- LIKE 패턴 값 [ESCAPE 이스케이프 문자]
- %: 아무 값들이 입력되어도 된다(값이 없어도 됨).
- _: 한 글자는 아무 값이 입력되어도 되지만 값이 있어야 한다.
select m from Member m where m.username like '%원%' -- 좋은회원, 회원, 원
select m from Member m where m.username like '회원%' -- 회원1, 회원ABC
select m from Member m where m.username like '%회원' -- 좋은회원, A회원
select m from Member m where m.username like '회원_' -- 회원A, 회원1
select m from Member m where m.username like '__3' -- 회원3
select m from Member m where m.username like '회원\%' ESCAPE '\' -- 회원%
5) NULL 비교식
- IS NULL
- NULL은 = 으로 비교하면 안되고 꼭 IS NULL을 사용해야 한다.
where m.username is null
where null = null -- 거짓
where 1=1 -- 참
5. 컬렉션 식
1) 빈 컬렉션 비교 식
- IS EMPTY
select m from Member m where m.orders is not empty
2) 컬렉션의 멤버 식
- MEMBER OF
select t from Team t where :memberParam member of t.members
6. 스칼라 식
1) 수학 식
- +, -: 단항 연산자
- *, /, +, -: 사칙연산
2) 문자함수
- CONCAT, SUBSTRING, TRIM, LOWER, UPPER, LENGTH, LOCATE
3) 수학함수
- ABS, SQRT, MOD, SIZE, INDEX
- SIZE: 컬렉션 크기
- INDEX: List 타입 컬렉션의 위치 값을 구함, 단 컬렉션이 @OrderColumn을 사용하는 List 타입일 때만 사용할 수 있다.
4) 날짜함수
- CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP
- 하이버네이트는 날짜 타입에서 년, 월, 일, 시간, 분, 초 값을 구하는 기능을 지원한다.
select CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP from Team t
-- 하이버네이트 지원 기능
select year(CURRENT_TIMESTAMP), month(CURRENT_TIMESTAMP), day(CURRENT_TIMESTAMP) from Member
7. CASE 식
1) 기본 CASE
select
case when m.age <= 10 then '학생요금'
when m.age >= 60 then '경로요금'
else '일반요금'
end
from Member m
2) 심플 CASE
select
case t.name
when '팀A' then '인센티브110%'
when '팀A' then '인센티브110%'
else '인센티브105%'
end
from Team t
3) COALESCE
- 스칼라식을 차례대로 조회해서 null이 아니면 반환한다.
select coalesce(m.username, '이름 없는 회원') from Member m
4) NULLIF
- 두 값이 같으면 null을 반환하고 다르면 첫 번째 값을 반환한다.
select nullif(m.username, '관리자') from Member m
10.2.11 다형성 쿼리
- JPQL로 부모 엔티티를 조회하면 자식 엔티티도 함께 조회한다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
@Getter @Setter
public abstract class Item {
@GeneratedValue @Id
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("Book")
@Getter @Setter
public class Book extends Item {
private String author;
}
-- SINGLE TABLE 전략(InheritanceType.SINGLE_TABLE)
select i.id, i.name, i.price, i.author, i.dtype
from Item i
-- JOIN 전략(InheritanceType.JOINED)
select i.id, i.name, i.price, b.author, i.dtype
from Item i
left outer join Book b on i.id=b.id
1. TYPE
- 엔티티 상속구조에서 조회 대상을 특정 자식 타입으로 한정할 때 주로 사용한다.
List<Item> items = em.createQuery("select i from Item i where type(i) in Book", Item.class).getResultList();
-- SINGLE TABLE 전략(InheritanceType.SINGLE_TABLE)
select i.id, i.name, i.price, i.author, i.dtype
from Item i
where i.dtype in ('Book')
-- JOIN 전략(InheritanceType.JOINED)
select i.id, i.name, i.price, b.author, i.dtype
from Item i
left outer join Book b on i.id=b.id
where i.dtype in ('Book')
2. TREAT
- 상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용한다.
- JPA 표준은 FROM, WHERE 절에서 사용할 수 있지만 하이버네이트는 SELECT 절에서도 사용할 수 있다.
List<Item> items = em.createQuery("select i from Item i where treat(i as Book).author = 'kim'", Item.class).getResultList();
-- SINGLE TABLE 전략(InheritanceType.SINGLE_TABLE)
select i.id, i.name, i.price, i.author, i.dtype
from Item i
where i.dtype='Book' and i.author='kim'
-- JOIN 전략(InheritanceType.JOINED)
select i.id, i.name, i.price, b.author, i.dtype
from Item i
inner join Book b on i.id=b.id
where b.author='kim'
10.2.12 사용자 정의 함수 호출
- 사용자 정의 함수를 등록하고 사용하는 기능이다.
- 방언 클래스를 상속하여 구현한다.
10.2.13 기타 정리
- enum은 = 비교 연산만 지원한다.
- 임베디드 타입은 비교를 지원하지 않는다.
1. EMPTY STRING
- JPA 표준은 ‘‘을 길이 0인 Empty String으로 정했지만 데이터베이스에 따라 ‘‘를 NULL로 사용하는 데이터베이스도 있으므로 확인해야한다.
2. NULL 정의
- 조건을 만족하는 데이터가 하나도 없으면 NULL이다.
- NULL은 알 수 없는 값이다. NULL과의 모든 수학적 계산 결과는 NULL이 된다.
- NULL == NULL 은 알 수 없는 값이다.
- NULL is NULL은 참이다.
10.2.14 엔티티 직접 사용
1. 기본 키 값
- JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값으로 변환된다.
Member result = em.createQuery("select m from Member m where m = :member", Member.class)
.setParameter("member", member)
.getSingleResult();
select m.id, m.age, m.team_id, m.username
from Member m
where m.id=?
2. 외래 키 값
- JPQL에서 m.team은 SQL에서 team_id 외래 키로 변환된다.
- JPQL에서 m.team을 연관 경로 표현식을 사용하여 묵시적 조인이 일어날 것 같지만 Member 테이블이 team_id 외래 키를 가지고 있으므로 묵시적 조인은 일어나지 않는다.
List<Member> result = em.createQuery("select m from Member m where m.team = :team", Member.class)
.setParameter("team", team1)
.getResultList();
select m.id, m.age, m.team_id, m.username
from Member m
where m.team_id=?
10.2.15 Named 쿼리: 정적 쿼리
- JPQL 쿼리는 동적 쿼리와 정적 쿼리로 나눌 수 있다.
- 동적 쿼리: em.createQuery(…) 처럼 런타임에 동적으로 JPQL을 구성하여 넘기는 것을 말한다.
- 정적 쿼리: 미리 정의한 쿼리에 이름을 부여해서 사용하는 것을 말한다. Named 쿼리라 한다.
- Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법을 체크하고 미리 파싱해둔다.
- 따라서 오류를 빨리 확인할 수 있고, 파싱된 결과를 재사용하므로 성능상 이점이 있다.
@Entity
@NamedQuery(name = "Member.findByUsername",
query = "select m from Member m where m.username = :username")
@Getter @Setter
public class Member {
}
List<Member> members = em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "member1")
.getResultList();
Leave a comment